I’m the author and owner of a similar code style/code quality package in a fairly large company and went through a very similar process, culminating with writing our own Roslyn-based analyzers to enforce various internal practices to supplant the customized configuration of the Microsoft provided analyzers. Also, we discovered that different projects need different level of analysis. We’re less strict with e.g test projects than core infrastructure. But all projects need to have the same formatting and style. That too can be easily done with one nuget using msbuild.
Agreed, it makes a huge difference.
Sadly Visual Studio made that difficult from the start of .net, given its history with attempting to hide the .csproj files from developers and thus reduce their exposure to it. Its a real shame they decided to build visual studio like that and didn't change it for years.
Now with sdk style project you just click on the project and the .*proj file comes up and is editable.
There's other little niggles, the Visual Studio gui for example offers a "pre-build" and "post-build" window that's kinda hacky. If you have more than one line in either of the windows the build no longer is able to push the _actual_ error back into the build. So its better to do this with separate target elements (that don't show up in this gui) or just run a pure msbuild file (.proj) to perform these tasks.
Older visual studio was just a bad habit generator/crutch which babied a lot of developers who could have learned better practices (i.e. more familiarity with msbuild) if they had been forced to.
That's like using a car for "traveling" 3 meters. Why not just use dotnet format + .editorconfig , they were created just for this purpose.
We have hundreds of repos, thousands of projects. It is hard to ensure consistency at scale with a local .editorconfig in every repo.
Also, with a nuget I can do a lot more than what editorconfig allows. Our package includes custom analyzers, custom spell check dictionaries, and multiple analysis packages (i.e not just the Microsoft provided analyzers). We support different levels of analysis for different projects based on project type (with automatic type detection). Not to mention that coding practices evolve with time, tastes, and new language features. And those changes also need to be consistently applied.
With a package, all we need to do to apply all of the above consistently across the whole company is to bump a single version.
And let the IDE take care of that. Pre-commit Hook and it's all done.
Any non-trivial thing to do is a pain to figure out if the documentation is not extensive enough.
I really love C#, but msbuild is one of the weak links to me, almost everything else is a joy to use.
Personally, I think there's too much baby in the MSBuild bathwater unfortunately and too much of the ecosystem is MSBuild to abandon it entirely. That said, I think MSBuild has improved a lot over the last few years. The Sdk-Style .csproj especially has been a great improvement that sanded a lot of rough edges.
I often really hate certain technologies like MsBuild and use them begrudgingly for years, fighting with the tooling, right up until I decide once and for all to give it enough of my attention to properly learn, and then realise how powerful and useful it actually is!
I went through the same thing with webpack too.
MsBuild is far from perfect though. I often think about trying to find some sort of simple universal build system that I can use across all my projects regardless of the tech stack.
I’ve never really dug much into `make`… Maybe something like that is what I’m yearning for.
I had a similar expreience with Cmake. Note, I still hate the DSL but what it can do and what you nowadays actually need to do (or how you organize it) if you are writing a new project can be relatively clean and easy to follow.
Not to say its easy to get to that point, but I don't think anyone really would say that.
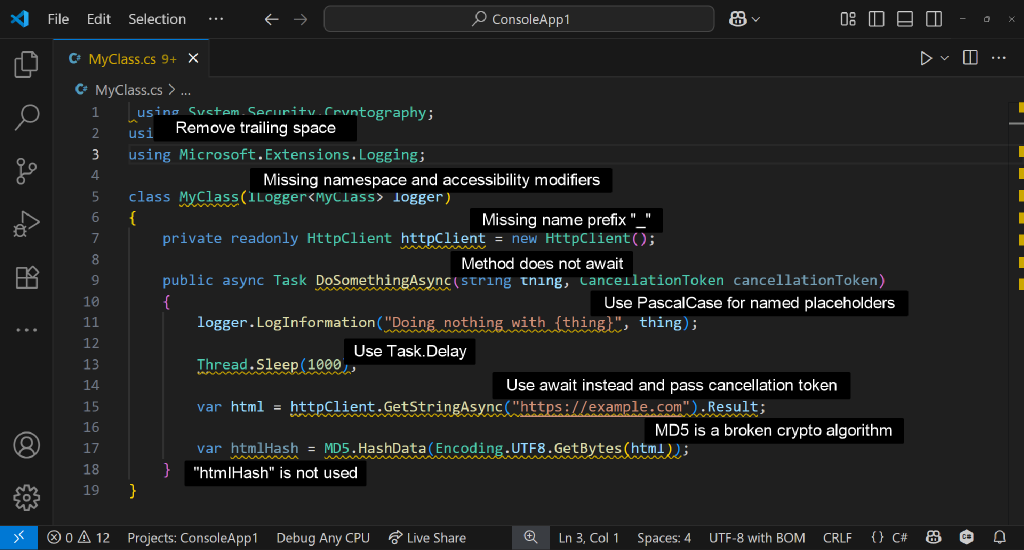
That screenshot looks like it was specifically written for the blog entry. (The project is called ConsoleApp1.)
I suspect the author didn't want to show their employer's proprietary code on their blog, and probably wanted to make a concise screenshot with multiple errors.
(Otherwise, they might have people who don't have a programming background occasionally writing non-production tools as part of a non-software-engineering job. This is quite common in many workplaces.)
[0] https://anthonysimmon.com/workleap-dotnet-coding-standards/w...
The code in the screenshot was written poorly on purpose, only for the need of this blog post.
Developers make mistakes at any level of seniority. It's less likely to happen when you reach a certain proficiency in writing C# code, but it's still a possibility. Mistakes can also go through some cracks at review time.
So these are definitely automated guardrails that don't require humans with specific knowledge to enforce them.
I don't agree. A better fitting comparison would be if a law firm enables spell checkers and proofreads documents to verify they use the law firm's letterhead. Do you waste your time complaining whether the space should go left or right of a bracket?
How do you expect junior programmers to become senior ones without help? Having automated guard-rails saves a large amount of your senior devs time by avoiding them having to pick such things up in code review, and you'll find the junior programmers absorb the rules in time and learn.
Several of the examples are nitpicking naming, this is exactly what should be automated. It's not like even experienced people won't accidentally use camelCase instead of PascalCase sometimes, or maybe accidentally snake_case something especially if they're having to mix C# back-end with JS frontend with different naming conventions.
Picking it up immediately in the IDE is a massive time-save for everyone.
The "There is an Async alternative" is a great roslyn rule. Depending on the API, some of those async overloads might not even have existed in the past, e.g. JSON serialisation, so having something to prompt "Hey, there's a better way to do this!" is actually magical.
Unused local variables are less likely, but they still happen, especially if a branch later has been removed. Having it become a compiler error helps force the dev to clean up as they go.
It’s definitely a tough balance to strike. I go back and forth on this myself.
Maybe the happy medium is to have everything strictly enforced in CI, relatively relaxed settings during normal dev loop builds and then perhaps a pre-commit build configuration that forces/reminds you to do one production build before pushing… (which if you miss, just means you may end up with a failed CI build to fix…)
I deleted it after realizing that the article actually does address this. But I'm still relieved that I'm not the only one with the dillema.
> which if you miss, just means you may end up with a failed CI build to fix…
Honestly as a developer if I miss this up until CI, that's on me. The important part is that these issues are still visible during the local development, even if as warnings, and that the developer knows (maybe after making that mistake once or twice :-)) that they can't just be ignored because they will fail down the road.
Yeah I agree. This has got me thinking a bit more actually about how to optimise build configurations much more deliberately. Dev loop builds vs “normal” (local) builds vs production builds.
I got into the habit of turning on TreatWarningsAsErrors in greenfield .NET projects, trying to be a disciplined developer… But often these warnings can be a distraction during fast iterations… I think I may change my policy…
https://learn.microsoft.com/en-us/dotnet/csharp/roslyn-sdk/t...
These suggestions being immediately executable can dramatically improve compliance. I find myself taking things like range operator syntax even though I don't really prefer it simply because the tool does the conversion automatically for me.
Just kind of giving up at this point. They are perfectly fine with waiting an extra day for every developer to finish simple tasks that better tooling could have helped with and I am not even talking about AI. Better database tools, better code refactoring that catches bugs before they happen. Lots of simple things.
How I approached it for an org with 300 projects and 10k+ failures after adding the analyzer.
1. Add .editorconfig and analyzer anyway
2. Ignore all the failing analyzer rules in .editorconfig
That's your baseline. Even if you have to ignore 80% of rules, that's still 20% of rules now being enforced going forward, which puts a stake in the ground.
Even if the .editorconfig doesn't enforce much yet, it allows incremental progress.
Crucially, your build still passes, it can get through code review, and it doesn't need to change a huge amount of existing code, so you won't cause massive merge issues or git-blame headaches.
3. Over time, take a rule from the ignored list, clean up the code base to meet that rule, then un-ignore.
How often you do such "weeding", and whether you can get any help with it, is up to you, but it's no longer a blocker, it's not on any critical path, it's just an easy way to pay down some technical debt.
Eventually you might be able to convince your team of the value. When they have fewer merge conflicts because there's fewer "random" whitespace changes. When they save time and get to address and fix a problem in private rather than getting to PR, etc.
Generally it's easier to ask forgiveness than permission. But you've got to also minimise the disruption when you introduce tooling. Make it easy for teammates to pick up the tooling, not a problem they now have to deal with.
Languages/tools that are not configurable and just dish out the will of the maintainers are objectively superior. This is all a weird type of mandatory bikeshedding; you need to do it, but it doesn't add anything of value to the product. Everyone is going to have a distinct opinion because they earned their programming chops at some shop that did things in some weird way.
.editorconfig is an anti-solution.
The big problem we had was an old codebase, with a very inconsistent style, that had a lot of code written by junior developers and non-developers.
This resulted in a situation where, every time I had to work in an area of the code I hadn't seen before, the style was so different I had to refactor it just to understand it.
.editorconfig (with dotnet-format) fixed this.
Prettier was relatively easy to adopt because most styles at the time were just eslint configurations and auto-formatters were scarce before Prettier. .NET has a long history of auto-formatters and most of them speak .editorconfig, so some interop would be handy, even if the goal isn't "perfect" interop. Just enough to build a pit of success for someone's first or second PR in a project before they get to that part of the Readme that says "install this thing in VS or Rider" or actually start to pay attention to the Workspace-recommended extensions in VS Code.
[0]: https://learn.microsoft.com/en-us/dotnet/core/tools/dotnet-f...
If everything is pretty stable, it's nice to have each developer share the work with keeping things up-to-date and functional. Broad automated test coverage makes this a lot easier of course.
We do, update packages every 3 months. Criticals are reported by a pipeline and are fixed same week.
The whole thing did not come out as a surprise for most of us. Even so, for those who were not aware of it, the benefits - as I captured screenshots of improvements highlighted from the warnings in their codebases after installing an alpha version of the package - were obvious.
Adoption was quite smooth and easy at first. Definitely not pushed onto teams for several weeks/months, until enough repos were onboarded and we had enough feedback that it would be beneficial for the whole company to use this.
Using an LLM wasn't about rewriting the whole thing, many sentences were left as before, so the style is definitely mine. It's okay if you don't like it, I'm trying to get better at it!
{kind=link}