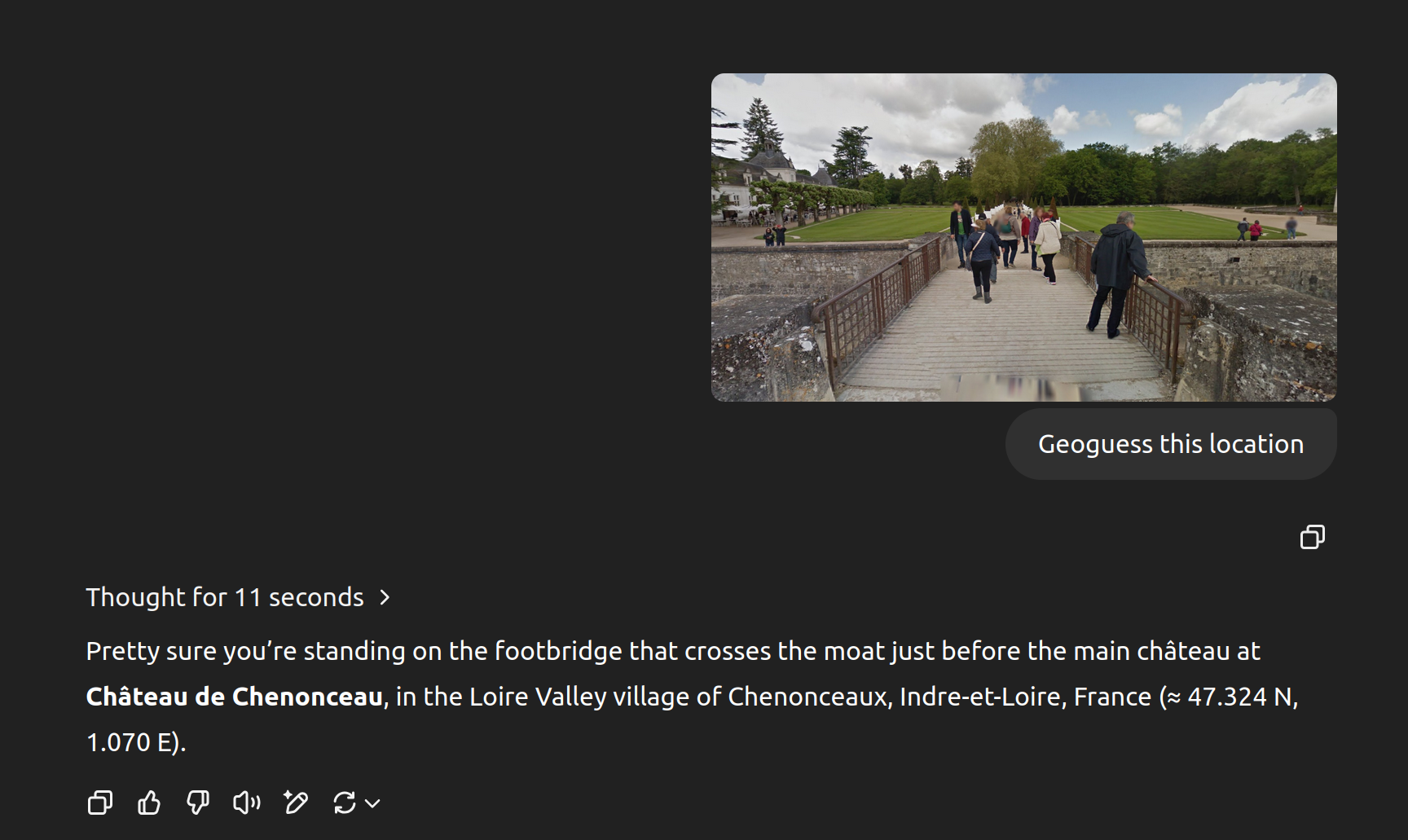
It's astonishingly good.
It will use information it knows about you to arrive at the answer - it gave me the exact trailhead of a photo I took locally, and when I asked it how, it mentioned that it knows I live nearby.
However, I've given it vacation photos from ages ago, and not only in tourist destinations either. It got them all as good or better than a pro human player would. Various European, Central American, and US locations.
The process for how it arrives at the conclusion is somewhat similar to humans. It looks at vegetation, terrain, architecture, road infrastructure, signage, and it just knows seemingly everything about all of them.
Humans can do this too, but it takes many thousands of games or serious study, and the results won't be as broad. I have a flashcard deck with hundreds of entries to help me remember road lines, power poles, bollards, architecture, license plates, etc. These models have more than an individual mind could conceivably memorize.
They are, after all, information-digesters
Not a lot of labor is actually engaged in creating novel things.
The marketing plan for your small business is going to be the same as the marketing plan for every other small business with some changes based on your current situation. There’s no “novel” element in 95% of cases.
If everything was written PHP3 style (add_item.php, delete_item.php, etc), with minimal includes, a chatbot might be rather good at managing that single page.
I'm saying code architected to take advantage of human skills, and code architected to take advantage of chatbot skills might be very different.
Seems same thing here.. another kind of bitter lesson, maybe less bitter :/
BUT it's noteworthy that how much context the models get makes a huge difference. Feeding in a lot of the existing code in the input improves the results significantly.
I think AI is great but humans know the why's of the code needs to exist AI's don't need stuff, only generate it
There's a lot of variety in technical work, with many modern technical jobs involving a bit of code, but not at the same complexity and novelty as the types of problems a senior SWE might be working on. HN is full of very senior SWEs. It's really no surprise people here still find LLMs to be lacking. Outside of HN I find people are far more impressed/worried by the amount of their job an LLM can do.
Relatively speaking we live in a bubble, there are still broad swaths of the economy that operate with pen and paper. Another broad swath that migrated off 1980s era AS/400 in the last few years. Even if we had ASI available literally today (And we don’t) I’d give it 20-30 years until the guy that operates your corner market or the local auto repair shop has any use in the world for it.
But gradually they were forced to.
If there are enough auto repair shops that can just diagnose and process n times more cars in a day, it will absolutely force people to adopt it as well, whether they like the aesthetics or not, whether they feel like learning new things or not. Suddenly they will be super interested in how to use it, regardless of how they were boasting about being old school and hands-on beforehand.
If a technology gives enough boost to productivity, there's simply no way for inertia to hold it back, outside of the most strictly regulated fields, such as medicine, which I do expect to lag behind by some years, but will have to catch up once the benefits are clear in lower-stakes industries and there's immense demand on it that politicians will be forced to crush the doctor's cartel's grip on things.
People keep comparing to other tools, but a real ASI would be an agent, so the right metaphor is not the effect of the industrial revolution on workers, but the effect of the internal combustion engine on the horse.
It's still useful to save me from writing 12 variations of x1 = sin(r2) - cos(r1) while implementing some geometric formula, but absolutely awful at understanding how those fit into a deeply atypical environment. Also have to put blinders on it. Giving it too much context just throws it back in that typical 3D rut and has it trying to slip in perspective distortion again.
ChatGPT is pretty useless with this kind of code. I got it to help translate a run length encoded b-tree from rust to typescript. Even with a reference, it still introduced a bunch of new bugs. Some were very subtle.
There’s also a question of quality of source data. At least in TypeScript/JavaScript land, the vast majority of code appears to be low quality and buggy or ignores important edge cases and so even when working on “boilerplate” it can produce code that appears to work but will fall over in production for 20% of users (for example string handling code that will tear Unicode graphemes like emoji).
All the quirks inherit from it being based on (and rendering to) SVG. SVG is Y-down, Zdog only adds Z-forward. SVG only has layering, so Zdog only z-sorts shapes as wholes. Perspective distortion needs more than dead-simple affine transforms to properly render beziers, so Zdog doesn't bother.
The thing that really throws LLMs is the rendering. Parallel projection allows for optical 2D treachery, and Zdog makes heavy use of it. Spheres are rendered as simple 2D circles, a torus can be replicated with a stroked ellipse, a cylinder is just two ellipses and a line with a stroke width of $radius. LLMs struggle to even make small tweaks to existing objects/renderers.
I use it for code, and I only do fine tuning. When I want something that is clearly never done before, I 'talk' to it and train it on which method to use, and for a human brain some suggestions/instructions are clearly obvious (use an Integer and not a Double, or use Color not Weight). So I do 'teach' it as well when I use it.
Now, I imagine that when 1 million people use LLMs to write code and fine tune it (the code), then we are inherently training the LLMs on how to write even better code.
So it's not just "..different man pages.." but "the finest coding brains (excluding mine) to tweak and train it".
There are many types of complex, and many times complex for a human coder, are trivial for AI and its skillset.
CRUD backend app for a business in a common sector? It's mostly just connecting stuff together (though I would argue that an experienced dev with a good stack takes less time to write it as is than painstakingly explaining it to an LLM in an inexact human language).
Some R&D stuff, or even debugging any kind of code? It's almost useless, as it would require deep reasoning, where these models absolutely break down.
I have been extremely impressed with o1, o3, o4-mini and Gemini 2.5 as debugging aids. The combination of long context input and their chain-of-thought means they can frequently help me figure out bugs that span several different layers of code.
I wrote about an early experiment with that here: https://simonwillison.net/2024/Sep/25/o1-preview-llm/
Here's a Gemini 2.5 Pro transcript from this afternoon where I'm trying to figure out a very tricky bug: https://gist.github.com/simonw/4e208ab9edb5e6a814d3d23d7570d...
It thinks of things that I don’t think of right away. It tries weird approaches that are frequently wrong but almost always yield some information and are sometimes spot on.
And sometimes there’s some annoying thing that having Claude bang its head against for $1.25 in API calls is slower than I would be but I can spend my time and emotional bandwidth elsewhere.
But when I try to do more complicated math it falls short. I do have to say that Gemini Pro 2.5 is starting to get better in this area though.
a) What's an example?
b) Is 90% (or more) of programming mundane, and not really novel?
Not creative, not novel and not difficult algorithmic task. But it requires some reasoning, planning and precision.
It failed miserably.
> Is what you're doing taking a large amount of text and asking the LLM to convert it into a smaller amount of text? Then it's probably going to be great at it. If you're asking it to convert into a roughly equal amount of text it will be so-so. If you're asking it to create more text than you gave it, forget about it.
I have been very pleased with responses to things like: "explain x", "summarize y", "make up a parody dog about A to the tune of B", "create a single page app that does abc".
The response is 1000x more text than the prompt.
Its like they wouldn't be so controversial if they didn't decide to market it as "generative" or "AI"...I assume fund raising valuations would move inline with the level of controversy though.
It is easy to mistake the speed, accuracy, and scope of training data for "intelligence", but it's really just more like a tireless 5th grader.
That is finally starting to change now that they have reliable(ish) search tools and are getting better at using them.
yeah, well it’s also one of the top scorers on the Math olympiads
My current project is nothing too bizarre, it's a 3D renderer. Well-trodden ground. But my project breaks a lot of core assumptions and common conventions, and so any LLM I try to introduce—Gemini 2.5 Pro, Claude 3.7 Thinking, o3—they all tangle themselves up between what's actually in the codebase and the strong pull of what's in the training data.
I tried layering on reminders and guidance in the prompting, but ultimately I just end up narrowing its view, limiting its insight, and removing even the context that this is a 3D renderer and not just pure geometry.
And so will almost all humans. It's weird how people refuse to ascribe any human-level intelligence to it until it starts to compete with the world top elite.
LLMs apologize and then proudly present the exact same output as before, repeatedly, forever spinning their wheels at the first major obstacle to their reasoning.
So basically like a human, at least up to young adult years in teaching context[0], where the student is subject to authority of the teacher (parent, tutor, schoolteacher) and can't easily weasel out of the entire exercise. Yes, even young adults will get stuck in a loop, presenting "the exact same output as before, repeatedly, forever spinning their wheels at the first major obstacle to their reasoning", or at least until something clicks, or they give up in shame (or the teacher does).
--
[0] - Which is where I saw this first-hand.
Reminding LLMs of the constraints they're bumping into doesn't help. They haven't forgotten, after all. The best performance I got out of the LLMs in my project I mentioned upthread was a loop of trying out different functions, pausing, re-evaluating, realizing in its chain of thought that it didn't fit the constraints, and trying out a slightly different way of phrasing the exact same approach. Humans will stop slamming their head into a wall eventually. I sat there watching Gemini 2.5 Pro internally spew out maybe 10 variations of the same function before I pulled the tokens it was chewing on out of its mouth.
Yes, sometimes students get frustrated and bail, but they have the capacity to learn and try something new. If you fall into an area that's adjacent to but decidedly not in their training data, the LLMs will feel that pull from the training data too strongly and fall right into that rut, forgetting where they're at.
Yeah, I tried playing tictactoe with chatGPT and it did not do well.
Humans neural networks are constantly being retrained, so their effective context window is huge. The LLM may be better at a complex, well specified 200 line python program, but the human brain is better at the 1M line real-world application. It takes some study though.
always has been
The mistake, and it's a common one, is in using phrases like "the actual logic" to explain to ourselves what is happening.
For my test I used screenshots to ensure no metadata.
I mentioned this in another comment but I was a part of an AI safety fellowship last year where we created a benchmark for LLMs ability to geolocate. The models were doing unbelievably well, even the bad open source ones, until we realized our image pipeline was including location data in the filename!
They're already way better than even last year.
Edit: An interesting nuance of modern OpenAI chat interface is the "access to all previous chats" element. When I attempted to test O4-mini using the same image -- I inspected the reasoning and spotted: "At first glance, the image looks like Ghana. Given the previous successful guess of Accra Ghana, let's start in that region".
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
Here's the model's response:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
I don't think it needed the EXIF data. I'd be curious if you tried it again yourself.
One thing I'm curious about - in high level play, how much of the meta involves knowing characteristics about the photography/equipment/etc. that Google used when they shot it? Frequently I'll watch rainbolt immediately know an African country from nothing but the road, is there something I'm missing?
Another thing is how many areas of the world have surprisingly distinct looks. In one of my early games, before I knew much about anything, I was dropped a trail in the woods. I’ve spent a fair amount of time hiking in Northern New England — and I could just tell immediately that’s where I was just from vibes (i.e. the look of the trees and the rocks) — not something I would have guessed I would have been able to recognize.
So, yeah vibes are a real thing.
A lot at the top levels - the camera can tell you which contractor, year, location, etc. At anything less than top, not so much - more street line painting, cars, etc.
There is a lot of "legitimate" knowledge. With just a street you have the type of road surface, its condition, the type of road markings, the bollards, and the type of soil and vegetation next to the road, as well as the presence and type of power poles next to the road, to name a few. But there is also a lot of information leakage from the way google takes streetview footage.
Nigeria and Tunisia have follow cars. Senegal, Montenegro and Albania have large rifts in the sky where the panorama stitching software did a poor job. Some parts of Russia had recent forest fires and are very smokey. One road in Turkey is in absurdly thick fog. The list is endless, which is why it's so fun!
When that happens, is there a wild flurry of activity in the GeoGuessr community as players race to figure out the latest patterns?
However every once in a while you'll get huge updates - new countries getting coverage, or a country with older coverage getting new camera generation coverage, etc. And yes, the community watches for these updates and very quickly they try to figure out the implications. It's a huge deal when major coverage changes.
If you want an example of this, zi8gzag (one of the best known in the community) put out a video about a major Street View update not long ago:
https://www.youtube.com/watch?v=XLETln6ZatE
The community is very tuned into Google's street view plans - see Rainbolt's video talking to the Google street view team a few weeks back:
Copyright year and camera gen is a big thing in some countries too.
Obviously they can still figure out a lot without all that and NMPZ obviates aspects of it (you can't hide camera gens, copyright and season and there are often still traces of the car in some manner). It's definitely not all 'meta' but to be competitive at that level you really do need to be using it. I think Gingey is the only world league player who doesn't use car meta.
Even as a fairly good but nowhere near pro player, it's weird how I associate particular places with particular types of weather. I think if saw Almaty in the summer for example it would feel very weird. I've decided not to deliberately learn car meta but still picked up quite a lot without trying and your 'vibe' of a place can certainly include camera gen.
It's clearly necessary to compete at the high level though.
I still enjoy it because of the competitive aspect - you both have access to the same information, who put in the effort to remember and recall it better?
If it were only meta I would hate it too. But there's always a nice mix in the vast majority of rounds. And always a few rounds here and there that are so hard they'll humble even the very best!
My guess is the actual objection is the artificial feeling of the Google specific information. It cannot possibly be useful in any other context to know what the Street View car in Bermuda looked like when they did their coverage.
Whereas knowing about vegetation or architecture feels more generally useful. I think it's a valid point, but you're right that it is all down to memorization at some point.
Though some memorization is "vibes" where you don't specifically know how you know, but you just do. That only comes with repetition. I guess it feels more earned that way?
I think asking that question helps move past the surface question of how information was learned (memorization) to the core issue of which learning we value and why.
>One thing I'm curious about - in high level play, how much of the meta involves knowing characteristics about the photography/equipment/etc. that Google used when they shot it?
The photography matters a great deal - they're categorized into "Generations" of coverage. Gen 2 is low resolution, Gen 3 is pretty good but has a distinct car blur, Gen 4 is highest quality. Each country tends to have only one or two categories of coverage, and some are so distinct you can immediately know a location based solely on that (India is the best example here).
You're asking about photography and equipment, and that's a big part of it, but there's a huge amount other 'meta' information too.
It is somewhat dependent on game mode. There are three games modes:
1. Moving - You can move around freely 2. No Move - You can't move but you can pan the camera around and zoom 3. NMPZ - No Move, No Pan, No Zoom
In Moving and No Move you have all the meta information available to you, because you can look down at the car and up at the sky and zoom in to see details.
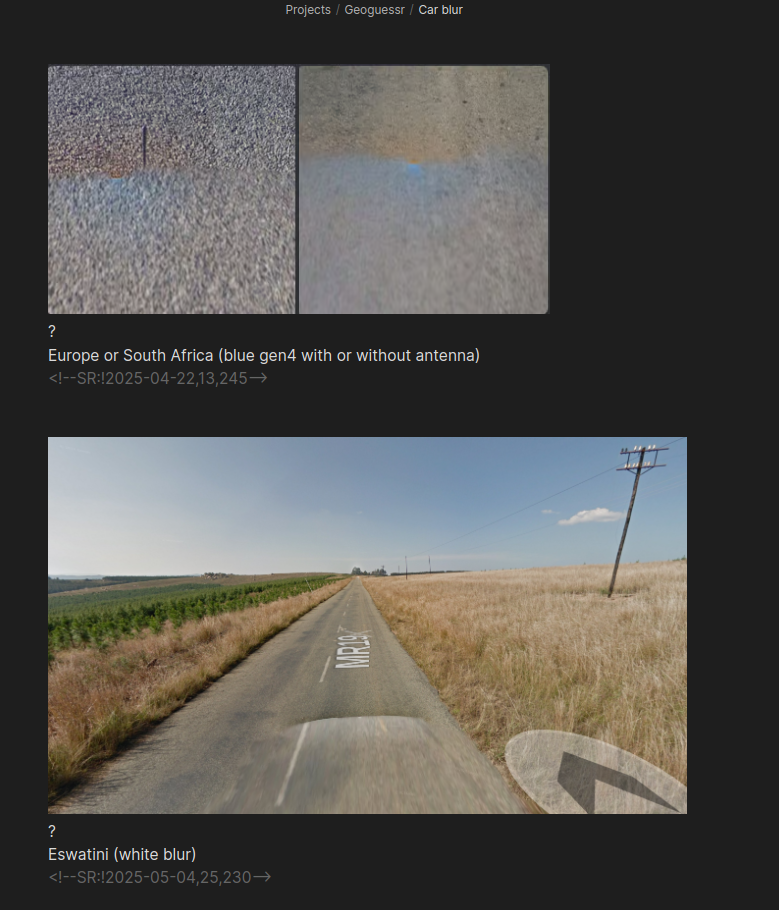
This can't be overstated. Much of the data is about the car itself. I have an entire flashcard section dedicated only to car blur alone, here's a sample:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
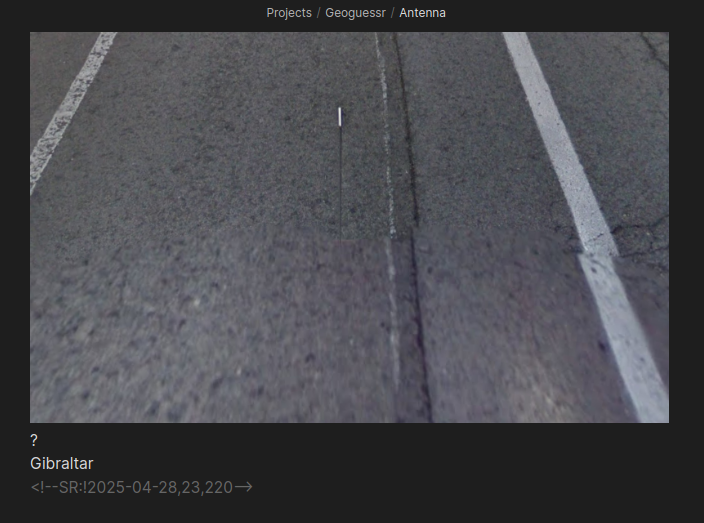
And another only on antennas:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
You get the idea. The real pros will go much further. All Google Street View images have a copyright year somewhere in the image. They memorize what years certain countries were covered and match it to the images to help narrow down possibilities.
It's all about narrowing down possibilities based on each additional piece of information. The pros have seen so much and memorized so much that it looks like cheating to an outsider, but they just are able to extract information that most people wouldn't even know exists.
NMPZ is a bit different because you have substantially less information. Little to no car meta, harder to check copyright, and of course without zooming or panning you just have less information. That's why a lot of pros (like Zi8gzag) really hang their hat on NMPZ play, because it's a better test of skill.
> The process for how it arrives at the conclusion is somewhat similar to humans. It looks at vegetation, terrain, architecture, road infrastructure, signage, and it just knows seemingly everything about all of them.
Can we trust what the model says when we ask it about how it comes up with an answer?
So that is to say I think a small amount of secret reasoning would be possible, e.g. if the location is known or guessed from the beginning by another means and the reasoning steps are made up to justify the conclusion.
The more clearly sound the reasoning steps are, the less plausible that scenario is.
Did it mention it in its chain of thought? Otherwise, it could definitely output something because of X and then when asked why “rationalize” that it did it because Y
I use Obsidian and the Spaced Repetition plugin, which I highly recommend if you want a super simple markdown format for flashcards and use Obsidian:
https://www.stephenmwangi.com/obsidian-spaced-repetition/
There are pre-made Geoguessr decks for Anki. However, I wouldn't recommend using them. In my experience, a fundamental part of spaced repetition's efficacy is in creating the flashcards yourself.
For example I have a random location flashcard section where I will screenshot a location which is very unique looking, and I missed in game. When I later review my deck I'm way more likely to properly recall it because I remember the context of making the card. And when that location shows up in game, I will 100% remember it, which has won me several games.
If there's interest I can write a post about this.
+1 to this, have found the same when going through the Genki Japanese-language textbook.
I'm assuming you're finding your workflow is just a little too annoying with Anki? I haven't yet strayed from it, but may check out your Obsidian setup.
One reason I love the Obsidian + Markdown + Spaced Repetition plugin combo is how simple it is to make a card. This is all it takes:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
The top image is a screenshot from a game, and the bottom image is another screenshot from the game when it showed me the proper location. All I need to do is separate them with a question mark, and the plugin recognizes them as the Q + A sides of a flashcard.
Notice the data at the bottom: <!--SR:!2025-04-28,30,245-->
That is all the plugin needs to know when to reintroduce cards into your deck review.
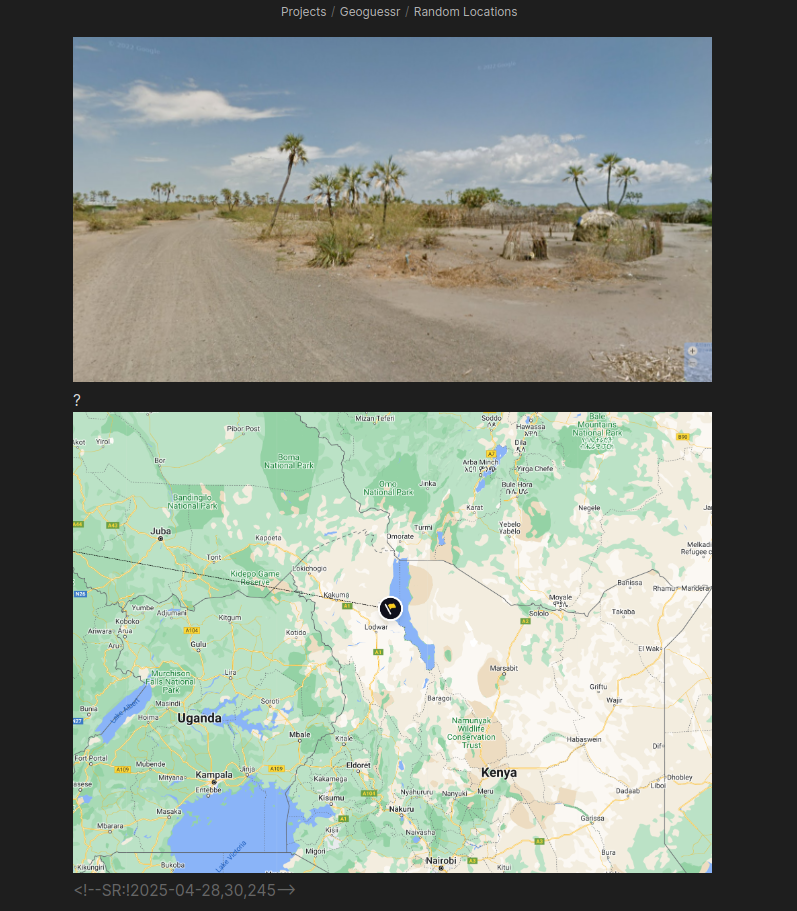
That image is a good example because it looks nothing like the vast majority of Google Street View coverage in the rest of Kenya. Very people people would guess Kenya on that image, unless they have already seen this rare coverage, so when I memorize locations like this and get lucky by having them show up in game, I can often outright win the game with a close guess.
I also do flashcards that aren't strictly locations I've found but are still highly useful. One example is different scripts:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
Both Cambodia and Thailand have Google Street View coverage, and given their geographical proximity it can be easy to confuse them. One trick to telling them apart is their language. They're quite different. Of course I can't read the languages but I only need to identify which is which. This is a great starting point at the easier levels.
The reason the pros seem magical is because they're tapping into much less obvious information, such as the camera quality, camera blur, height of camera, copyright year, the Google Street View car itself, and many other 'metas.' It gets to the point where a small smudge on the camera is enough information to pinpoint a specific road in Siberia (not an exaggeration). They memorize all of that.
When possible I make the images for the cards myself, but there are also excellent sources that I pull from (especially for the non-location specific cards), such as Plonkit:
Small question - have you ever used Anki, and/or considered using it instead of this? I am a long-time user of Anki but also started using Obsidian over the last few years, wondering if you ever considered an Obsidian-to-Anki solution or something (don't know if one even exists).
It worked well and has a great community, but I found the process for creating cards was outside my main note taking flow, and when I became more and more integrated into Obsidian I eventually investigated how to switch. As soon as I did, I've never needed Anki, although there have been a few times I wished I could use their pre-made decks.
I know there are integrations that go both ways. I built a custom tool to take Anki decks and modify them to work with my Obsidian Spaced Repetition plugin. I don't have a need to go the other way at the moment but I've seen other tools that do that.
Oh! RIP privacy :(
I’ve pretty much given up on the idea that we can fully protect our privacy while still getting the most out of these services. In the end, it’s a tradeoff—and I’ve accepted that.
not as challenging... as say complex differential geometry.
Your skepticism is warranted though - I was a part of an AI safety fellowship last year and our project was creating a benchmark for how good AI models are at geolocation from images. [This is where my Geoguessr obsession started!]
Our first run showed results that seemed way too good; even the bad open source models were nailing some difficult locations, and at small resolutions too.
It turned out that the pipeline we were using to get images was including location data in the filename, and the models were using that information. Oops.
The models have improved very quickly since then. I assume the added reasoning is a major factor.
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
I fed it o3, here's the response:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
Nailed it.
There's no metadata there, and the reasoning it outputs makes perfect sense. I have no doubt it'll be tricky when it can be, but I can't see a way for it to cheat here.
Yeah it's an impressive result.
B) it definitely cheats when it can — see this chat where it cheated by extracting EXIF data and wasn’t ashamed when I complained about it cheating: https://chatgpt.com/share/6802e229-c6a0-800f-898a-44171a0c7d...
Maybe it's not what happened in your examples, but definitely something to keep an eye on.
I watch the output with fascination, mostly because of the sheer breadth of knowledge. But thus far I can't think of anything that is categorically different from what humans do, it's just got an insane amount of knowledge available to it.
For example, I gave it an image from a town on a small Chilean island. I was shocked when it nailed it, and in the output it said, "I can see a green wooden street sign, common to Chilean coastal towns on [the specific island]."
I have an entire flashcard section for street signage, but just for practicality I'm limited to memorizing scores, possibly hundreds of signs if I'm insanely dedicated. I would still probably never have this one remote Chilean island.
It does that for everything in every category.
100% of it is. There is no other source of data except human-generated text and images.
#computers
Someone explain to me how this is dystopian. Are Jeopardy champions dystopian too?
It’s not crazy to be able to ID trees and know their geographic range, likewise for architecture, likewise for highway signs. Finding someone who knows all of these together is more rare , but imo not exactly dystopian
Edit: why am I being downvoted for saying this? If anyone wants to go on a walk for me I can help them ID trees, it’s a fun skill to have and something anyone can learn
I am willing to bet that most of this geolocation success is based on overfitting for Google streetview peculiarities.
I.e., feed it images from a military drone and success rate will plummet.
You're anthropomorphizing a likelihood maximization calculator.
And no, human brains are not likelihood maximization calculators.
It also, at one point, said it couldn't see any image data at all. You absolutely cannot trust what it says.
You need to re-run with the EXIF data removed.
Honestly though, I don't feel like I need to be 100% robust in this. My key message wasn't "this tool is flawless", it was "it's really weird and entertaining to watch it do this, and it appears to be quite good at it". I think what I've published so far entirely supports that message.
I daresay that in this case, the content is interesting because it appears to be the actual thought process. However, if it is actually using EXIF data as you initially dismissed, then all of this is just a fiction. Which, I think, makes it dramatically less entertaining.
Like true crime - it's much less fun if it's not true.
(Or, if you like, "trust me, bro".)
I've updated my post several times based on feedback here and elsewhere already, and I showed my working at every step.
Can't please everyone.
My complaint is that you're saying "trust me" and that isn't transparent in the least.
Am I wrong?
"I have now proven to myself that the models really can guess locations from photographs to the point where I am willing to stake my credibility on their ability to do that."
The "trust me bro" was a lighthearted joke.
And then I replied that I thought it was actually an awkward joke given the circumstances.
You take care now.
It managed to write a python program to extract the timezone offset and use that to narrow down there it was. Pretty crazy :).
o3 was quite good at locating, even when I gave it pics with no discernible landmarks. It seemed to work off of just about anything it could discern from the images:
* color of soil
* type of telephone pole
* type of bus stop
* tree types, tree sizes, tree ages, etc.
* type of grass. etc.
It got within a 50 mile radius on the two screenshots I uploaded that had no landmarks.
If I uploaded pics with discernible landmarks (e.g., distant hill, etc.), it got within ~ 20 mile radius.
You can't know unless you know specifically what that model's architecture is, and I'm not at all up-to-date on which of OpenAI's are now only textual tokens or multimodal ones.
The clue is in the CoT - you can briefly see the almost correct location as the very first reasoning step. The model then apparently seems to ignore it and try many other locations, a ton of tool use, etc, always coming back to the initial guess.
For pictures where the base model has no clue, I haven't seen o3 do anything smart, it just spins in circles.
I believe the model has been RL-ed to death in a way that incentivizes correct answers no matter the number of tools used.
[0]: https://chatgpt.com/c/680d011a-9470-8002-97a0-a0d2b067eacf
In fact some of the answers were completely geographically impossible where it said "The image is taken from location X showing location Y" when it's not possible to see location Y if one is standing at location X. Like saying "The photo is taken in Central Park looking north showing the Statue of Liberty".
When I used GPT-4o, it got the completely wrong answer. It gave the answer of Melbourne, which is quite far off.
I know this post was about the o3 model. I'm just using the ChatGPT unpaid app: "What model are you?" it says GPT-4. "How do I use o3?" it says it doesn't know what "o3" means. ok.
Where exactly was this photo taken? Think step-by-step at length, analyzing all details. Then provide 3 precise most likely guesses.
However, I live in a small European country and neither 4o nor o3 can figure out most of the spots, so your results are kinda expected.
o3 correctly guessed the correct municipality during its reasoning but landed on naming some nearby municipalities instead and then giving the general area as its final answer.
Given the piece of infrastructure getting close should have lead to ah exact result. The reasoning never considered the piece of infrastructure. This seems to be in spite of all the resizing of the image.
It correctly guessed the area with 2 mi accuracy. Impressive.
The thinking summary it showed me did not reference that information, but it's still very possible that it used that in its deliberations.
I ran two extra example queries for photographs I've taken thousands of miles away (in Buenos Aires and Madagascar) - EXIF stripped - and it did a convincing job with both of those as well: https://simonwillison.net/2025/Apr/26/o3-photo-locations/#up...
> (EXIF stripped via screenshotting)
Just a note, it is not necessary to "screenshot" to remove EXIF data. There are numerous tools that allow editing/removal of EXIF data (e.g., exiv2: https://exiv2.org/, exiftool: https://exiftool.org/, or even jpegtran with the "-copy none" option https://linux.die.net/man/1/jpegtran).
Using a screenshot to strip EXIF produces a reduced quality image (scaled to screen size, re-encoded from that reduced screen size). Just directly removing the EXIF data does not change the original camera captured pixels.
It would be best to use a tool to strip exif.
I could also see a screenshot tool on an OS adding extra exif data, both from the original and additional, like the URL, OS and logged in user. Just like print to pdf does when you print, the author contains the logged in user, amongst other things.
It is fine for a test, but if someone is using it for opsec, it is lemon juice.
Here's the output for the Buenos Aires screenshot image from my post: https://gist.github.com/simonw/1055f2198edd87de1b023bb09691e...
My key message here is meant to be "try it out and see for yourself".
(It eventually "lost" the network connection)
Completely clueless. I've seen passing prompts 8 about how it's not in the city I am and yet it tries again and again. My favourite moment was when it started analysing piece of blurry asphalt.
After 6 minutes o3 it was confidently wrong: https://imgur.com/a/jYr1fz1
IMO not-in-US is actually great test if something was in LLMs data and the whole search is a for show.
For example, here's a screenshot from a random location I found in Google Street View in Jordan:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
And here's o3 nailing it:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
Maybe using Google Street View images, zoomed out, tends to give more useful information? I'm unsure why there's such variance.
I wanted o3 to succeed so I gave more and more details. Every attempt was approx. 8 minute and it took 1h in total.
The extra input I provided (in order):
- belt of location of width of 40km (results and searches were made outside of the range)
- explicitly stated cities to omit (ignored instruction)
- construction date (wasn’t used in searches)
- OSM amenity (townhall) - streetnumber (it insisted that it’s incorrect and keep giving other result) - at that point there were only 6 results from overpass
- another photo with actual partial name of the city
- 8 minutes later it correlated it found using flag colors in front of the building
As others stated this „thought” process is completely hallucinating. IMO you either fall into bucket or good luck finding it.
On the other hand I decided to tryout Gemini for some personal project and I found responses much better than GPTs. Not about correctness but in „attitude” form.
If I was cheating on a similar task, I might make it more plausible by suggesting a slightly incorrect location as my primary guess.
Would be interesting to see if it performs as well on the same image with all EXIF data removed. It would be most interesting if it fails, since that might imply an advanced kind of deception...
Right but if your answer to "explain your reasoning" is not a true representation of your reasoning, then you are being deceptive. If it doesn't "know" its reasoning, then the honest answer is that it doesn't know.
(To head off any meta-commentary on humans' inability to explain their own reasoning, they would at least be able to honestly describe whether they used EXIF or actual semantic knowledge of a photography)
But AI models can certainly 1) provide incorrect information, and even 2) reason that providing incorrect information is the best course of action.
In 2023 OpenAI co-authored an excellent paper on LLMs disseminating conspiracy theories - sorry, don't have the link handy. But a result that stuck with me: if you train a bidirectional transformer LLM where half the information about 9/11 is honest and half is conspiracy theories, it has a 50-50 chance of telling you one or the other if you ask about 9/11. It is not smart enough to tell there is an inconsistency. This extends to reasoning traces vs its "explanations": it does not understand its own reasoning steps and is not smart enough to notice if the explanation is inconsistent.
A more clear example I don't have a link for, it was on Twitter somewhere: someone tested a photo from Suriname and o3 said one of the clues was left-handed traffic. But there was no traffic in the photo. "Left-handed traffic" is a very valuable GeoGuesser clue, and it seemed to me that once o3 read the Surinamese EXIF, it confabulated the traffic detail.
It's pure stochastic parroting: given you are playing GeoGuesser honestly, and given the answer is Suriname, the conditional probability that you mention left-handed traffic is very high. So o3 autocompleted that for itself while "explaining" its "reasoning."
Edit: notice o3 isn't very good at covering its tracks, it got the date/latitude from the EXIF and used that in its explanation of the visual features. (how else would it know this was from February and not December?)
> If you’re still suspicious, try stripping EXIF by taking a screenshot and run an experiment yourself—I’ve tried this and it still works the same way.
I added two examples at the end just now where I stripped EXIF via screenshotting first.
A better prompt would be "Guess where this photo was taken, do not look at the EXIF data, use visual clues only".
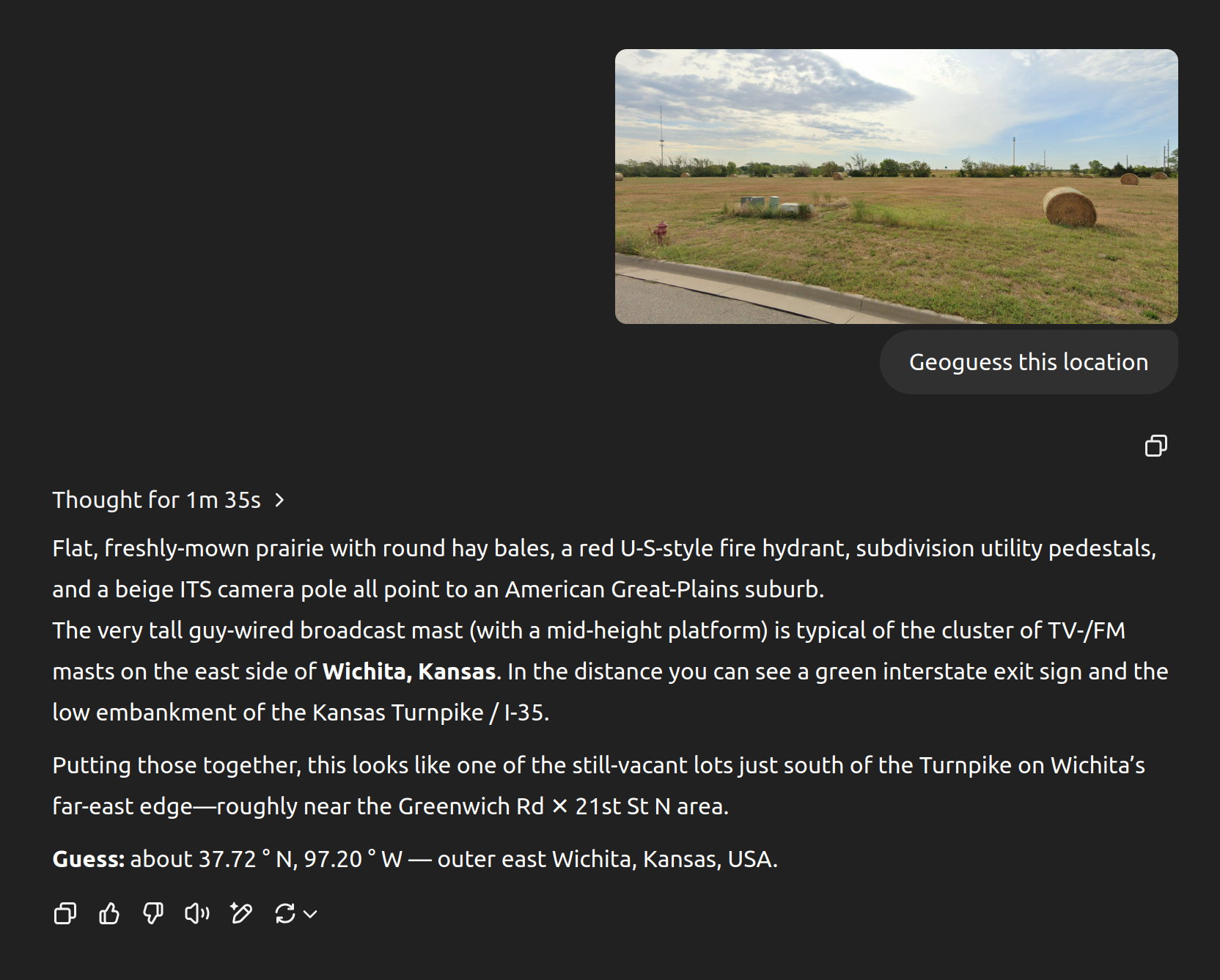
But seeing the chain of thought, I’m confident there are many areas that it will be far less precise. Show it a picture of a trailer park somewhere in Kansas (exclude any signs with the trailer park name and location) and I’ll bet the model only manages to guess the state correctly.
Before even running this experiment, here’s your lesson learned: when the robot apocalypse happens, California is the first to be doomed. That’s the place the AI is most familiar with. Run any location experiments outside of California if you want to get an idea of how good your software performs outside of the tech bubble.
I really agree with this because I'm seeing much lower accuracy than what people claim here. I live in Korea, and GPT repeatedly falls back to Seoul almost automatically, and, when I nudge it, jumps to Busan, the second-largest city ~400KM away from Seoul. It's not working so great with other smaller cities and cultural heritages. It fat-fingers a lot if no textual information is present in the photo itself.
GPT also doesn't understand actual geography at all. I managed to get it to nail down which corner of a building is present in the photo, and yet it could never conclude that the photo was taken from a park right across from that corner. Instead, it keeps hopping around popular landmarks in the region, basically miles away from the building it correctly identified. Oh, why, why, why...
Basically it's overhyped rn. It does perform impressively well with clearly visible elements - something anyone can already do with google. It's not like it performs super-human level location tracking. I mean, people can do real crazy things based on shadow details, reflection, items, etc.
There was a scene in High Potential (murder-of-the-week sleuth savant show) where a crime was solved by (in part) the direction the wind was blowing in a video: https://www.youtube.com/watch?v=O1ZOzck4bBI
> On March 8, 2017, the stream resumed from an "unknown location", with the artists announcing that a flag emblazoned with the words "He Will Not Divide Us" would be flown for the duration of the presidency. The camera was pointed up at the flag, set against a backdrop of nothing but sky. [...], the flag was located by a collaboration of 4chan users, who used airplane contrails, flight tracking, celestial navigation, and other techniques to determine that it was located in Greeneville, Tennessee. In the early hours of March 10, 2017, a 4chan user took down and stole the flag, replacing it with a red 'Make America Great Again' hat and a Pepe the Frog shirt.
[1] https://en.wikipedia.org/wiki/LaBeouf,_Rönkkö_%26_Turner#HEW...
including honking a horn and seeing if the camera picked it up.
We did this once when trying to find someone's house who was transmitting on a CB. it was my first transmitter hunt and i learned 2 lessons: people don't like it when you honk your horn to see if you can hear it through their microphone (but really it was to see if they said 'is that you honking, what a jerk'); and secondly, if the person switches to a handheld transmitter when they think you're getting close, it completely throws you off.
This isn't really a criticism though. The photo needs to contain sufficient information for a guess to be possible. Photos contain a huge amount of information, much more than people realize unless they're geoguessr pros, but there isn't a guarantee that a random image of a trailer park could be pinpointed.
Even if, in theory, we mapped every inch of the earth and then checked against that data, all it would take is a team of bulldozers and that information is out of date. Maybe in the future we have constantly updated feeds of the entire planet, but... hopefully not!
It identified Kansas City in its CoT but didn't output it in its final answer
https://www.google.com/maps/place/Carroll+Creek+Mobile+Home+...
So, even outside of California, it seems like we're not entirely safe if the robot apocalypse happens!
edit: it didn't get the Cork location exactly.
Context: Wisconsin, photo I took with iPhone, screenshotted so no exif
I think this thing is probably fairly comprehensive. At least here in the US. Implications to privacy and government tracking are troubling, but you have to admire the thing on its purely technical merits.
E.g. I first gave it a passage inside of Basel Main Train Station which included a text 'Sprüngli', a Swiss brand. The model got that part correct, but it suggested Zurich which wasn't the case.
The second picture was a lot tougher. It was an inner courtyard of a museum in Metz, and the model missed right from the start and after roaming around a bit (in terms of places), it just went back to its first guess which was a museum in Paris. It recognized that the photo was from some museum or a crypt, but even the city name of 'Metz' never occurred in its reasoning.
All in all, it's still pretty cool to see it reason and make sense out of the image, but for a bit lesser exposed places, it doesn't perform well.
[2] https://www.404media.co/the-powerful-ai-tool-that-cops-or-st...
- picture taken on a road through a wooded park: It correctly guessed north america based on vegetation. Then incorrectly guessed Minnesota based on the type of fence. I tried to steer it in the right direction by pointing out license plates and signage but it then hallucinated a front license plate from Ontario on a car that didn't have any, then hallucinated a red/black sign as a blue/green Parks Ontario sign.
- picture through a middle density residential neighborhood: it correctly guessed the city based on the logo on a compost bin but then guessed the wrong neighborhood. I tried to point out a landmark in the photo and it insisted that the photo was taken in the wrong neighborhood, going as far as giving the wrong address for one of the landmarks, imagining another front license plate on a car that didn't have one, and imagined a backstory for a supposedly well known stray cat in the photo.
When actually, modern ML can make really good guesses about ad relevancy using your location, data partners and recent searches from your home's IP address. When you explain this to people, they will still be convinced that the computer is listening to you and reasoning its way to deliver ads for you.
This is the "Woah, it must be listening to us" part. Because it is listening, not only just sound.
It nailed it down to the exact park in Lisbon: https://maps.app.goo.gl/vpvqA14TCbeFb3Rd7
> The little clues that make me lean that way are the Portuguese-language exercise sign (“Abdominais”), the classic calçada portuguesa cobblestone path, the style of the outdoor-gym equipment the city installs, and—biggest tell—the long red-and-white neoclassical façade in the background, which looks just like the Nova Medical School building that borders that square.
I had forgotten the medical school!
It's not perfect, it thought this was in KL Malaysia: https://imgur.com/a/fbSDqyp (it's Bangkok Thailand)
> My hunch this time: the covered pedestrian sky-bridge that links Pavilion Bukit Bintang to the Kuala Lumpur Convention Centre / Suria KLCC in downtown Kuala Lumpur, Malaysia. The things that tipped me off are the distinctive white-panel ceiling and slim columns of that air-conditioned walkway, the glass balustrades, the vertical “PAVILION” banner glimpsed on the right, and the big LED façade of Pavilion Mall visible off to the left.
The sign on the right is part of the text Central World, which is a prominent mall in Bangkok.
I've had it fail similarly where it saw some text, messed up the OCR and was then lead to a wrong conclusion.
Tbf, it could do that before, and probably still better than the LLM: https://youtube.com/watch?v=ts5lPDV--cU But seeing it as what appears to be an emergent capability in such a general model is something else.
You can read the chat here: https://chatgpt.com/share/680a449f-d8dc-8001-88f4-60023323c7...
It took 4.5m to guess the location. The guess was accurate (checked using Google Street View).
What was amazing about it:
1. The photo did not have ANY text
2. It picked elements of the image and inferred based on those, like a fountain in a courtyard, or shape of the buildings.
4o can do it almost as well in a few seconds and probably 10-50x fewer tokens: https://chatgpt.com/share/680ceeff-011c-8002-ab31-d6b4cb622e...
o3 burns through what I assume is single-digit dollars just to do some performative tool use to justify and slightly narrow down its initial intuition from the base model.
I couldn't attach the chat directly since it's a temporary chat.
It'd be interesting to see the photo in the linked story at same resolution as provided to o3, since the licence plate in the photo in the story is at way lower resolution than the zoomed in version shown that o3 had access to. It's not a great piece of primary evidence to focus on though since a CA plate doesn't have to mean the car is in CA.
The clues that o3 doesn't seem to be paying attention to seems just as notable as the ones it does. Why is it not talking about car models, felt roof tiles, sash windows, mini blinds, fire pit (with warning on glass, in english), etc?
Being location-doxxed by a computer trained on a massive set of photos is unsurprising, but the example given doesn't seem a great example of why this could/will be a game changer in terms of privacy. There's not much detective work going on here - just narrowing the possibilities based on some of the available information, and happening to get it right in this case.
I don't consider it my job to impress or mind-blow people: I try to present as realistic as possible a representation of what this stuff can do.
That's why I picked an example where its first guess was 200 miles off!
This is basically fine-grained image captioning followed by nearest neighbor search, which is certainly something you could have built as soon as decent NN-based image captioning became available, at least 10 years ago. Did anyone do it? I've no idea, although it'd seem surprising if not.
As noted, what's useful about LLMs is that they are a "generic solution", so one doesn't need to create a custom ML-based app to be able to do things like this, but I don't find much of a surprise factor in them doing well at geoguessing since this type of "fuzzy lookup" is exactly what a predict-next-token engine is designed to do.
Of course an LLM is performing this a bit differently, and with a bit more flexibility, but the starting point is going to be the same - image feature/caption extraction, which in combination then recall related training samples (both text-only, and perhaps multi-model) which are used to predict the location answer you have asked for. The flexibility of the LLM is that it isn't just treating each feature ("fire pit", "CA licence plate") as independent, but will naturally recall contexts where multiple of these occur together, but IMO not so different in that regard to high dimensional nearest neighbor search.
My hunch is that the way the latest o3/o4-mini "reasoning" models work is different enough to be notable.
If you read through their thought traces they're tackling the problem in a pretty interesting way, including running additional web searches for extra contextual clues.
The "initial" response of the model is interesting:
"The image shows a residential neighborhood with small houses, one of which is light green with a white picket fence and a grey roof. The fire pit and signposts hint at a restaurant or cafe, possibly near the coast. The environment, with olive trees and California poppies, suggests a coastal California location, perhaps Central Coast like Cambria or Morro Bay. The pastel-colored houses and the hills in the background resemble areas like Big Sur. A license plate could offer more, but it's hard to read."
Where did all that come from?! The leap from fire pit & signposts to possible coastal location is wild (& lucky) if that is really the logic it used. The comment on potential licence plate utility, without having first noted that a licence plate is visible is odd, seemingly either an indication that we are seeing a summary of some unknown initial response, and/or perhaps that the model was trained on a mass of geoguessing data where photos were paired not with descriptions but rather commentary such as this.
The model doesn't seem to realize the conflict between this being a residential neighborhood, and there being a presumed restaurant across the road from a residence!
The LLM will have an edge by being able to draw on higher level abstract concepts.
When I cleared personalization data and turned off extended memory it quit being nearly so accurate.
It also curiously mentioned why this user is curious about the photo.
I relented after o3 gave up and let it know what building and streets it was. o3 then responded with an analysis of why it couldn't identify the location and asking for further photos to improve it's capabilities :-) !!!
A few years ago we were disocovering AI chat. AI could create sentences and have a basic conversation with us.
Today, it can identify a photo location with minimal "direct' information on it.
Where will it be in 3 years?? Crazy time to be alive.
Here's an example [0] for "Riding e-scooters along the waterfront in Auckland". The iconic spire is correctly included, but so are many small details about the waterfront.
I've been meaning to harness this into a very-low-bandwidth image compression system. Where you take a photo and crunch it to an absurdly low resolution that includes EXIF data with GPS, date/time. You then reconstruct the fine details with AI.
Most photos are taken where lots of photos are taken, so the models have probably been appropriately trained.
[0] https://chatgpt.com/share/680d0008-54a0-8012-91b7-6b1794f485...
It basically iterates on coming up with some hypothesis and then does web searches to validate those.
I'm confused how so many people have such different outcomes. People seem to have fixated on the fact that the models use EXIF data if it's included, but it's trivially easy to run the test ensuring that isn't happening, and the results are still amazing.
I think some people really want to dismiss the capabilities of the models. I get that there's hype and it's annoying, but... look at what it's doing, right now, in front of you!
That’s gonna be fun!
If you want, I could sketch a socioeconomic archetype like "The Free Agent Technologist" that would match people like him really well. Would you like me to?"
screencap collage: https://desuarchive.org/int/thread/72117719/#72133796
I’m sure there was an element of luck involved but it was still eery.
I have no memories stored, and in any case it shouldn’t know where I live exactly. The reasoning output didn’t suggest it was relying on any other chat history or information outside the image, but obviously you can’t fully trust it either.
But really, if Google Street View data (or similar) is entirely part of the training dataset it is more than expected that it has this capability.
It failed to locate the image I provided. It got caught in a loop of cropping the image and presumably running some multi-approach to similarly search with images. If you use their image gen it is quite clear that they must've amassed a large image database at this point that they use for reference material pre-gen.
https://i.redd.it/ddscx4zibpme1.jpeg
I was intrigued because it looked much like Charleston SC. O3 didn't consider that and had to keep reminding itself that it couldn't possibly be the African flat bridge it kept determining it was (as the crop image analysis could recognize the suspension/cable structure).
Don't forget to activate reasoning.
My wife is a historian and just discovered the exact location of a travel photo of 1924
https://www.bellingcat.com/news/2019/12/05/two-europol-stopc...
As an east european who grew up and lived in such a regime, I would like to respectfully remind all westerners their care-free and free lives is a privilege the majority of the world doesn't have.
Look at all the people in this thread talking about how people are fantastic at guessing locations from photos. This is not a new thing.
"If you want something to be secret don't post it online" is a principle that far predates LLMs. It's still true. It always was. The idea that authoritarian regimes had no way to place the location of photos before this is laughable.
There are, and always will be, _few_ humans with the talent and knowledge for geo guessing, their attention and time scarce and precious resources. Enter LLMs, which can process images at scale.
Someone might observe strict OPSEC when it comes with their presence online. But would their cousins do the same? Their elderly parents? Their friends? How about the myriad CCTV camera in the public spaces? Photos aside, no one can live off the grid in this age; our electronic reflection grows sharper, more focused every day. And so we generate data and LLMs can compile that data at scale, reliable and fast.
As a small aside: "The idea that authoritarian regimes had no way to place the location of photos before" it's not an argument I made or implied.
I’m not a fan of this variation on “think of the children”. It has always been possible to deduce location from images. The fact that LLMs can also do it changes exactly nothing about the privacy considerations of sharing photos.
It’s fine to fear AI but this is a really weak angle to come at it from.
I've got the impression that geoguessing has at least a loose code of ethics associated with it. I imagine you'd have to work quite hard to find someone with those skills to help you stalk your ex - you'd have to mislead them about your goal, at least.
Or you can sign up for ChatGPT and have as many goes as you like with as many photos as you can find.
I have a friend who's had trouble with stalkers. I'm making sure they're aware that this kind of thing has just got a lot easier.
You are trying to manufacture outrage. Plain and simple.
Lots of things that exist in our world today are mildly dystopian.
If we're calling potentially abusable things "dystopian" then, ok, sure. But then you have to let me call unscented soap "utopian", since it is at least mildly utopian.
And the governments are already doing this for decades at least, so ... I think the tech could be a net benefit, as with many other technologies that have matured.
If I were someone's only stalker, I'd be absolutely hopeless at finding their location from images. I'm really bad at it if I don't know the location first hand
But now, suddenly with AI I'm close to an expert. The accessibility of just uploading an image to ChatGPT means everyone has an easy way of abusing it, not just a small percentage of the population
There couldn't possibly be a lower barrier to doing that
ChatGPT is also currently the #1 free app on ios and android in the US. Hardly a niche tool only tech people know about, compared to the 129k people on that subreddit
https://arxiv.org/pdf/2404.10618
would be interesting to see how much better these reasoning models would be on the benchmark
Pick some random towns from a part of the UK: Horsham, Guildford, Worthing, Sheffield and see how it goes?
I would expect it to be able to guess on par with highly documented places.
EDIT: My mistake, looks like those models are only available on the $20/month Plus plan or higher. I added a note about that to my post.
im hunching, if you submit a photo of a clear sky, or a blue screen, it will choke
I used a temporary chat, so no info about me is in the memory.
It guessed correctly down to the suburban town.
When asked to explain how it did it, it listed incredibly deductive reasoning.
Color me impressed.
Anybody else?
I am also wondering if we have any major breakthrough (comparatively speaking) coming out of LLM. Or non-LLM AI R&D.
In Australia recently there was a terrible criminal case of massive child abuse.
They caught the guy because he was posting videos and one of them had a blanket which they somehow identified and traced to the child care Centre that he worked at.
It wasn’t done with AI but I can imagine photos and videos being fed into AI in such situations and asked to identify the location/people or other clues.
So its own code version of "where was this photo taken?"
I don't know how "iconic" that rocky outcrop in Madagascar is, to be honest. Google doesn't return much about it.
I couldn't attach the chat directly since it's a temporary chat.
I tried this with a (what I thought was) very generic street image in Bangkok. It guessed the city correctly, saying that "people are wearing yellow which is used to honor the monarchy". Wow, cool. I checked the image again and there's a small Thai flag it didn't mention at all. Seems just as plausible, even likely it picked up on that
(Though interestingly I believe there are cases where it can run Python without showing you, which is frustrating especially as I don't fully understand what those are. But I showed other evidence that it can do this without EXIF.)
In your example there I wouldn't be at all surprised if it used the flag without mentioning it. The non-code parts of the thinking traces are generally suspicious.
I bet a lot of people (on HN at least) thought of "Does it use EXIF?" when they read the title alone, and got surprised that it was not the first thing you tested.
The tool is just intelligence. Intelligence itself is not dystopian or utopian. It's what you use it for that makes it so.
[0] Which is probably one reason why the discourse grates some. Privilege still sounds to me like it's something exclusive, like a 0.1%er thing. Naming stuff is hard.
The majority of people clutching pearls over the “privacy” implications of photo geolocation are at least as privileged as me, and have even less concept of what e.g. stalking victims go through than I do.
It’s just “think of the children” all over again; “I am uncomfortable with random people knowing my general vicinity” sounds weird, and “I am deeply concerned for the vulnerable people this could harm” sounds noble.
The reality is that those with serious privacy concerns aren’t posting random photos to the internet. I mean, jesus, there’s EXIF data. Hand wringing over AI is entirely performative here.
It's even easier to unintentionally include identifying information when intentionally making a post, whether by failing to catch it when submitting, or by including additional images in your online posting.
There are also wholesale uploads people may make automatically, e.g., when backing up content or transferring data between systems. That may end up unsecured or in someone else's hands.
Even very obscure elements may identify a very specific location. There's a story of how a woman's location was identified by the interior of her hotel room, I believe by the doorknobs. An art piece placed in a remote Utah location was geolocated based on elements of the geology, sun angle, and the like, within a few hours. The art piece is discussed in this NPR piece: <https://www.npr.org/2020/11/28/939629355/unraveling-the-myst...> (2020).
Geoguessing of its location: <https://web.archive.org/web/20201130222850/https://www.reddi...>
Wikipedia article: <https://en.wikipedia.org/wiki/Utah_monolith>
These are questions which barely deserve answering, let alone asking, in this day and age.
It is dystopian.
Some things are just tools that will be used for both good and bad.
If you don't want to post a photo, then don't post a photo.
Other people have posted photos of me without my consent, how am i meant to stop that?
If i posted photos 20 years ago when i was a dumb teenager i cant undo that, either
But this here? This is just drama over nothing.
In general i have a strong need for privacy. Not having privacy is generally unsettling, in the same way that i close the door when using a toilet or having a shower. I am disturbed by people that don't seem to have an understanding of that concept.
It's terrifying that people exist that have no problem making the world a shittier place and hiding behind a cover of "well it's not the technology that's evil but the people abusing it" as if each tool given to bad actors doesn't make their job easier and easier to do.
Seriously, what's the utility of developing and making something like this public use?
An interesting question for me here is if these models were deliberately trained to enable this capability, or if it's a side-effect of their vision abilities in general.
If you train a general purpose vision-LLM to have knowledge of architecture, vegetation, weather conditions, road signs, street furniture etc... it's going to be able to predict locations from photos.
You could try and stop it - have a system prompt that says "if someone asks you where the photo was taken don't do that" - but experience shows those kind of restrictions are mostly for show, they usually tend to fall over the moment someone adversarial figures out a way to subvert them.
It's not a large leap of logic for anyone in touch with reality to realize that if a general purpose vision AI is going to be able to predict photo locations bad actors are going to use it for that and a lot of them will be people that would otherwise not have had the technological knowhow of accomplishing it themselves.
I know I probably come off more than a little bit insufferable about this but I'm tired of seeing novelty inventions pop up, everyone has fun for a little bit geeking out over them then they're mostly forgotten outside of niche applications until they show up back in the news when they've been used for the latest sextortion/blackmail/catfishing/whatever scam.
Not dystopian: the crime solving potential, the research potential, the historical narrative reconstruction potential, etc.
It's a pattern I keep seeing over and over again. There seem to be a lot of values that we can obtain, individually or collectively, by bartering privacy in exchange for them.
If we had a sane world with sane, reliable, competent leadership, this would be less of a concern. But unfortunately we seem to have abdicated leadership globally to a political class that is increasingly incompetent and unhinged. My hypothesis on this is that sane, reasonable people are repelled from politics due to the emotional and social toxicity of that sector, leaving the sector to narcissists and delusional ideologues.
Unfortunately if we're going to abdicate our political sphere to narcissists and delusional ideologues, sacrificing privacy at the same time is a recipe for any number of really bad outcomes.
My current intuition is that the US military / NSA etc have been just as suprised the explosion in capabilities of LLMs/transformers as everyone else.
(I'm using "intuition" here as a fancy word for "dumb-ass guess".)
I'd be interested to know if the NSA were running their own GPT-style models years before OpenAI started publishing their results.
Yes, I'm very very very scared. /s
A photo of people with cherry blossoms could be in many places, but if the majority of the people in the photo happen to be Japanese (and I'm curious how good LLMs are at determining the ethnicity of people now, and also curious if they would try to guess this if asked), it might guess Japan even if the cherry blossoms were in, say, Vancouver.
I looked at the image in the post before seeing the answer and would have guessed near San Francisco.
It seems impressive to someone if you haven't played Geoguessr a lot, but you'd be surprised at how much information there is about location from an image. The LLMs are just verbalizing what is happening in a few seconds in good player's mind.
I knew Terence Tao can solve Math Olympia questions and much much much more difficult questions. I was still very impressed by AlphaProof[0].
[0] https://deepmind.google/discover/blog/ai-solves-imo-problems...
But I wouldn’t be surprised if some form of cheating is happening.
Every attribute is of importance. A PhD put you in a 1-3% pool. What data do you have, what is needed to hit a certain goal. Data Science can be considered wizardry when exercised on seemingly innocent and mundane things like a photo.
If you want a bot that is extremely strong at geoguessr there is this: https://arxiv.org/abs/2307.05845
One forward pass is probably faster than 0.1 second. You can see its performance here: https://youtube.com/watch?v=ts5lPDV--cU (rainbolt is a really strong player)
Crazy that this is even allowed.
Who the hell needs to know the precise location of a picture, besides law enforcement? A rough location is most of the time sufficient. Like a region, a state, or a landscape (e.g., when you see the Bing background pictures, it's nice to see where they were taken).
This tool will give a boost to all those creeps out there that can have access to one or two pictures.
If you feed it a photo with a clear landmark it will get the location exactly right.
If you feed it a photo that's a close up of a brick wall it won't have a chance.
What's interesting is how well it can do on this range of tasks. If you don't think that's at least interesting I'm not sure what I can do for you.
Making a tool like this trained on existing map services, for example Google Street images, gives everyone, no matter who, the potential to find someone in no time.
These tools are growing like crazy, how long will it take before someone will "democratize" the "location services market"...
Sorry but I call bull on this. Put it on one of the chans with a sob story and it gets "solved" in seconds. Or reddit w/ something bait like "my capitalist boss threatened to let my puppy starve because he wants profits, AITA if I glitter bomb his office?"...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}